

Optical character recognition (OCR) is a technology used to convert scanned paper documents, in the form of PDF files or images, into searchable, editable data.
The Syncfusion OCR processor library has extended support to OCR process PDF documents and other scanned images in the .NET Core platform from version Create an ASP.NET Core web application.
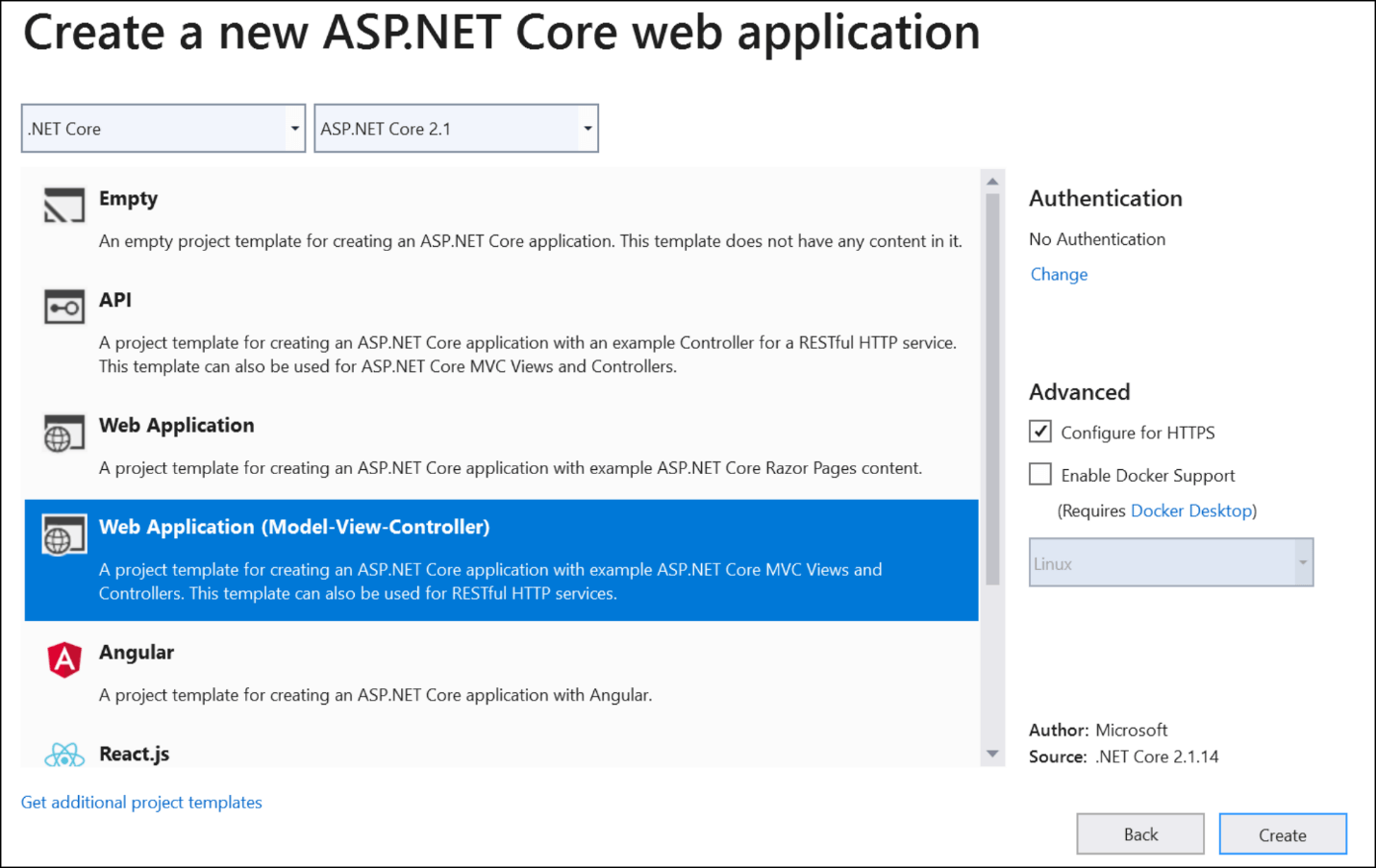
Create an ASP.NET Core web application
Follow these steps to create an ASP.NET Core web application in Visual Studio 2019:
- In Visual Studio 2019, go to File > New and then select Project.
- Select Create a new project.
- Select the ASP.NET Core Web Application template.
- Enter the Project name and then click Create. The Project template dialog will be displayed.
Install necessary NuGet packages to OCR process PDF documents
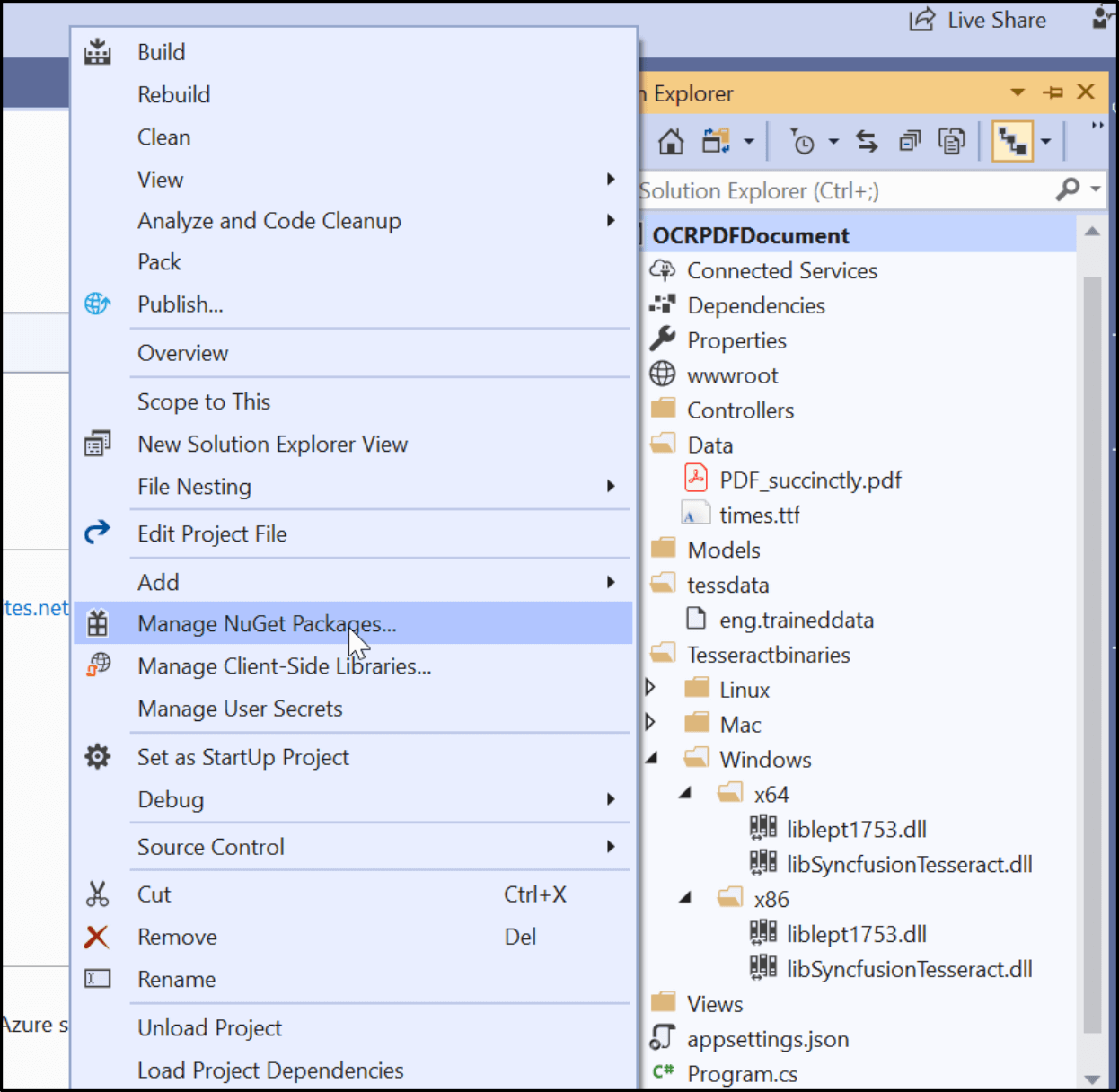
Follow these steps to install the Syncfusion.PDF.OCR.Net.Core NuGet package in the project:
- Right-click on the project and select Manage NuGet Packages.
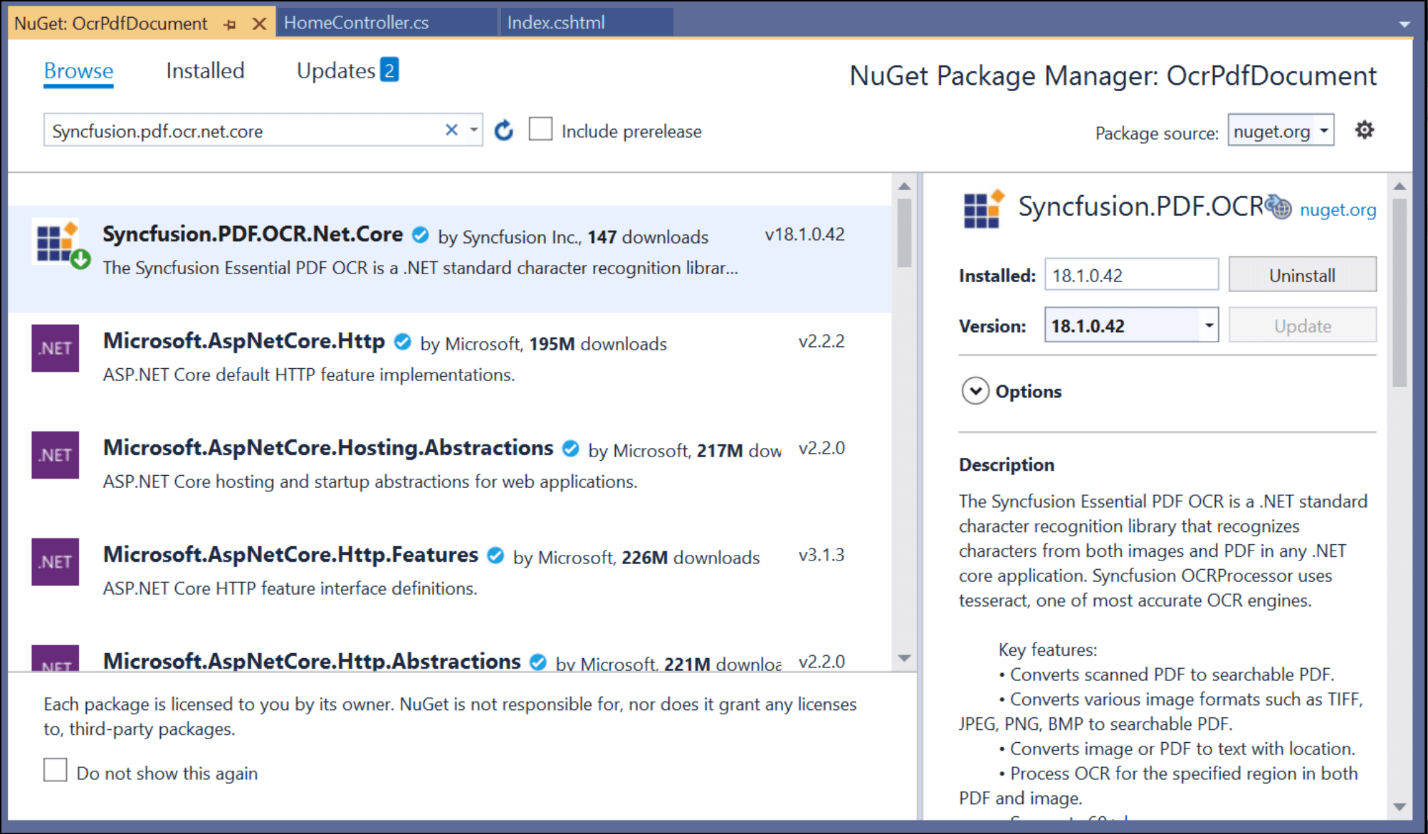
- Search for the Syncfusion.PDF.OCR.Net.Core package and install it.
Perform OCR processing on PDF document
Follow these steps to perform OCR processing on a PDF document in ASP.NET Core:
- Syncfusion’s OCR processor internally uses Tesseract libraries to perform OCR, so please copy the necessary tessdata and TesseractBinaries folders from the NuGet package folder to the project folder to use the OCR feature. The tessdata folder contains OCR language data and Tesseractbinaries contains the wrapper assemblies for Tesseract OCR. Please use the following link to download OCR language data for other languages.
https://github.com/tesseract-ocr/tessdata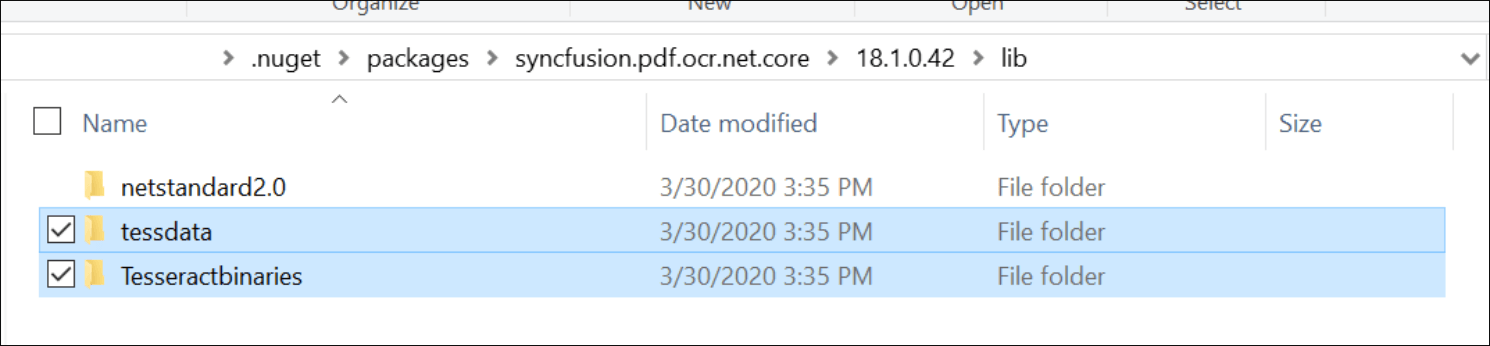
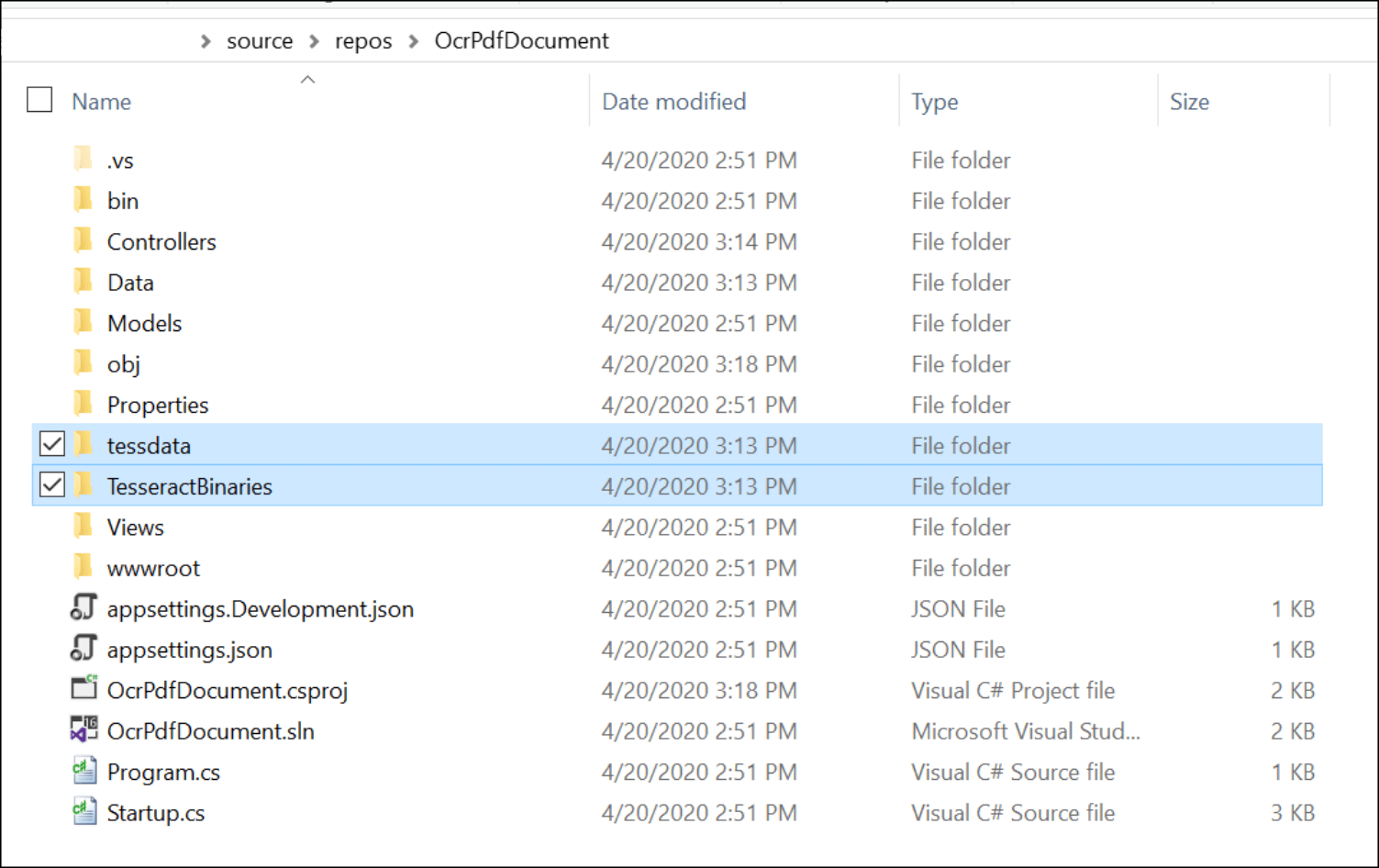
- Set Copy to Output Directory to Copy if newer for Data, tessdata, and TesseractBinaries folders.
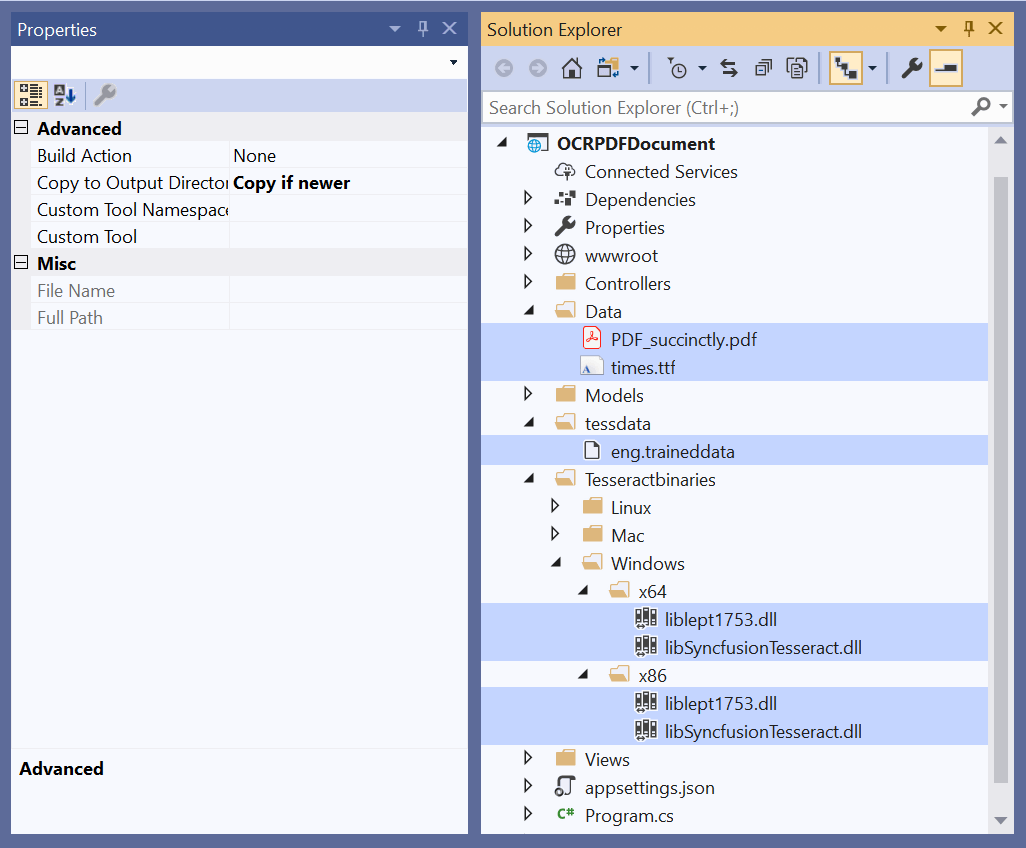
- Add a new button in index.cshtml.
@{ Html.BeginForm("PerformOCR", "Home", FormMethod.Post); { <input type="submit" value="Perform OCR" class=" btn" /> } } - Include the following namespaces in HomeController.cs.
using Microsoft.AspNetCore.Hosting; using Microsoft.AspNetCore.Mvc; using Syncfusion.OCRProcessor; using Syncfusion.Pdf.Graphics; using Syncfusion.Pdf.Parsing; using System.IO; - Include the following code example in HomeController.cs to perform the OCR processing.
public IActionResult PerformOCR() { string binaries = Path.Combine(_hostingEnvironment.ContentRootPath, "TesseractBinaries", "Windows"); //Initialize OCR processor with tesseract binaries. OCRProcessor processor = new OCRProcessor(binaries); //Set language to the OCR processor. processor.Settings.Language = Languages.English; string path = Path.Combine(_hostingEnvironment.ContentRootPath, "Data", "times.ttf"); FileStream fontStream = new FileStream(path, FileMode.Open); //Create a true type font to support unicode characters in PDF. processor.UnicodeFont = new PdfTrueTypeFont(fontStream, 8); //Set temporary folder to save intermediate files. processor.Settings.TempFolder = Path.Combine(_hostingEnvironment.ContentRootPath, "Data"); //Load a PDF document. FileStream inputDocument = new FileStream(Path.Combine(_hostingEnvironment.ContentRootPath, "Data", "PDF_succinctly.pdf"), FileMode.Open); PdfLoadedDocument loadedDocument = new PdfLoadedDocument(inputDocument); //Perform OCR with language data. string tessdataPath = Path.Combine(_hostingEnvironment.ContentRootPath, "Tessdata"); processor.PerformOCR(loadedDocument, tessdataPath); //Save the PDF document. MemoryStream outputDocument = new MemoryStream(); loadedDocument.Save(outputDocument); outputDocument.Position = 0; //Dispose OCR processor and PDF document. processor.Dispose(); loadedDocument.Close(true); //Download the PDF document in the browser. FileStreamResult fileStreamResult = new FileStreamResult(outputDocument, "application/pdf"); fileStreamResult.FileDownloadName = "OCRed_PDF_document.pdf"; return fileStreamResult; }
By executing this example, you will get the PDF document shown in the following image.

Publish OCR application in Azure App Service
Follow these steps to publish the OCR application in Azure App Service:
- In Solution Explorer, right-click the project and choose Publish (or use the Build > Publish menu item).
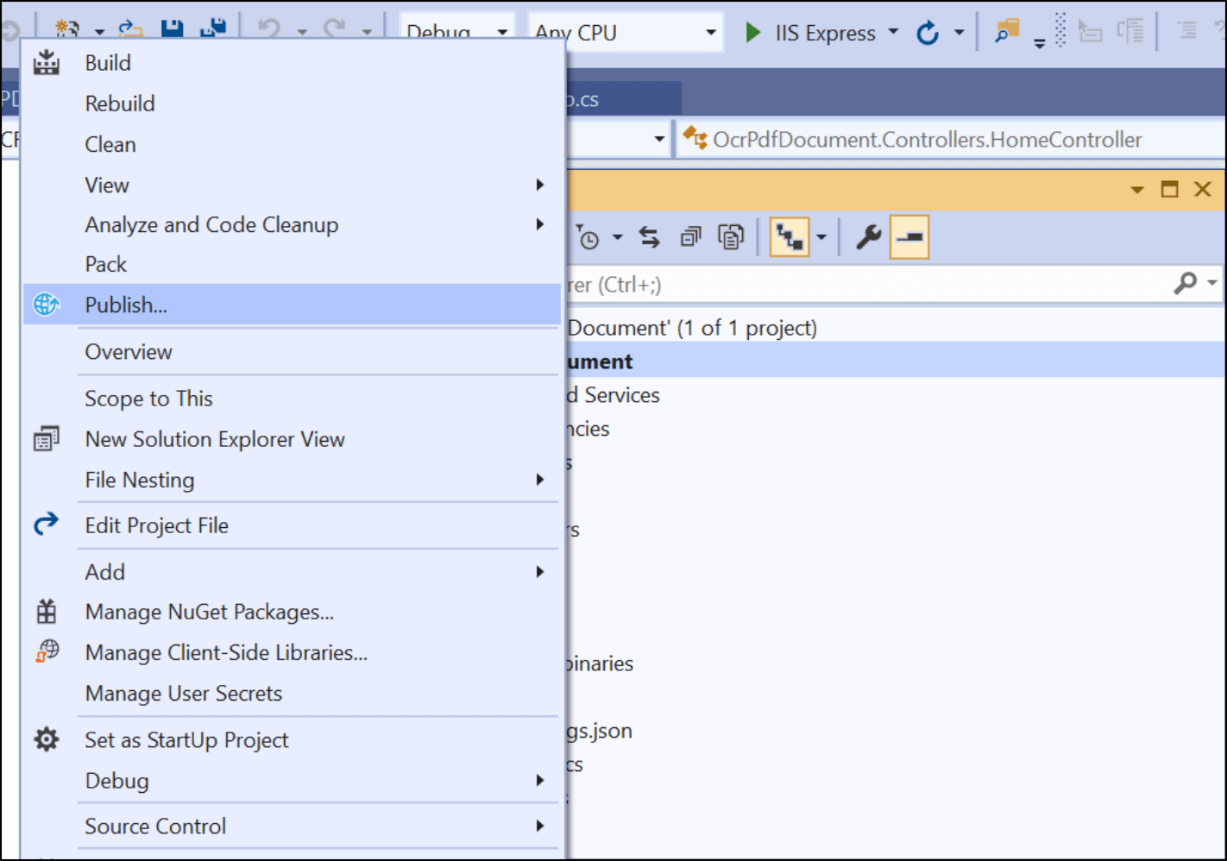
- In the Pick a publish target dialog box, choose App Service, select Create New and click Create Profile.
- In the Create App Service dialog box that appears, sign in with your Azure account (if necessary). Then, the default app service settings populate the fields. Click Create.

- Visual Studio now deploys the app to your Azure App Service, and the web app loads in your browser. The project properties Publish pane shows the site URL and other details. Click Publish to publish the application in Azure App Service.
After publishing the application, you can perform OCR processing by navigating to the site URL.
Note: Adobe provides an easy-to-use method for turning scanned files into editable PDF documents instantly, with editable text and custom fonts that look just like the original file. For more details, refer to the article How to edit scanned documents.
GitHub reference
You can find examples of performing OCR on ASP.NET Core applications and Azure App Service in the GitHub repository.
Conclusion
In this blog post, we have learned to perform OCR processing on PDF documents in ASP.NET Core web applications and publish the applications in Azure App Service.
Take a moment to peruse our documentation, where you’ll find other options and features, all with accompanying code examples.
If you have any questions about these features, please let us know in the comments below. You can also contact us through our support forum, Direct-Trac, or feedback portal. We are happy to assist you!
If you liked this article, we think you would also like the following articles about our PDF Library:
 No spam, just valuable updates.
No spam, just valuable updates.


Comments (4)
Object reference not set to an instance of an object on tessdataPath.
Hi NAMFON,
Thank you for using Syncfusion products.
On our further analysis, the reported issue occurs due to the provided TTF font file is not valid. We are trying to install this font on our end, but we could not able to install the font.
However, we can resolve this issue by providing a valid TTF font. We have replaced the proper TTF font in the sample and it’s working fine.
Please find the download link below,
https://www.syncfusion.com/downloads/support/directtrac/general/ze/OCR.API224324897-1938474588
Please let us know if you need any further assistance with this.
Regards,
Gowthamraj K
On IIS – Could not find a part of the path ‘C:\inetpub\wwwroot\mysite\x64’ – despite it is working locally without any issue..
When debugging tesseractbinaries path on IIS – the path it is valid, so statments:
var tesseractBinariesPath = ConfigurationHelper.MapPath(“Tesseractbinaries\\Windows\\”);
var tesseractDataPath = ConfigurationHelper.MapPath(“tessdata\\”);
which gives on IIS gives following results:
C:\inetpub\wwwroot\mysite\Tesseractbinaries\Windows\
C:\inetpub\wwwroot\mysite\tessdata
and tesseract files are in that location (C:\inetpub\wwwroot\mysite\Tesseractbinaries\Windows\x64)
Custom MapPath function is looking like this:
public static string MapPath(string path) {
path = path.Replace(“~\\”, “”);
return Path.Combine(env.ContentRootPath, path);
}
BUT when instancing OCR processor, I’m getting error:
Could not find a part of the path ‘C:\inetpub\wwwroot\mysite\x64’
I don’t understand from where OCRProcessor searches for and gets ‘C:\inetpub\wwwroot\mysite\x64’ and why it is so confused on IIS when in local development is working normally..
Hi DR
The reported exception may occur due to missing or mismatched assemblies of the Tesseract binaries and Tesseract data from the OCR processor. We have created a sample to perform the OCR operation with the test document, it is working properly. We are unable to reproduce the reported exception on our end. Please make sure the path of the Tesseract binaries and Tesseract data are provided properly. Kindly please try the below sample on your end and let us know the result.
Sample: https://www.syncfusion.com/downloads/support/directtrac/general/ze/OCRCoreSample782347509
Note: The above sample contains the Tesseract binaries and Tess data folder in a project location.
Please refer to the below link for more information,
UG: https://help.syncfusion.com/file-formats/pdf/working-with-ocr/dot-net-core
Troubleshooting: https://help.syncfusion.com/file-formats/pdf/working-with-ocr/dot-net-core#troubleshooting
OCR processor required read/write and execute permission of the temporary and Tesseract binaries folder. If the temporary folder does not have elevated permission, the reported exception may occur. So, kindly ensure the respective user group has permission for the temp and Tesseract folder. When hosting the application to IIS, our processor makes use of the system temporary folder (By default, C://Windows//Temp). So, please make sure this temp path, the binaries path has required permission for the respective user group (IIS_IUSRS). If you are hosting the application in IIS, please try to add the IIS_IUSRS user group and provide full access permission to the temp folder.
If you still face the same exception, we request you to share the modified sample or complete code snippet, input document, environment details (such as OS, bit version, culture settings, etc) Syncfusion product version, Tesseract version, output document, product version to check the issue in our end. So, it will be helpful for us to analyze and assist you further on this.
Regards,
Gowthamraj K