
Assembly Language Succinctly®

CHAPTER 2
Fundamentals
Now that we have some methods for coding assembly, we can begin to examine the language itself. Assembly code is written into a plain text document that is assembled by MASM and linked to our program at compile time or stored in a library for later use. The assembling and linking is mostly done automatically in the background by Visual Studio.
Note: Assembly language files are not said to be compiled, but are said to be assembled. The program that assembles assembly code files is called an assembler, not a compiler (MASM in our case).
Blank lines and other white space is completely ignored in the assembly code file, except within a string. As in all programming, intelligent use of white space can make code much more readable.
MASM is not case sensitive. All register names, instruction mnemonics, directives, and other keywords need not match any particular case. In this document, they will invariably be written as lowercase in any code examples. Instructions and registers will be written in upper case when referred to by name (this convention has been adopted from the AMD programmer's manuals, and it makes register names easier to read).
Note: If you would like MASM to treat variable names and labels in a case sensitive way, you can include the following option at the top of your assembly code file: "option casemap: none."
Statements in assembly are called instructions; they are usually very simple and do some tiny, almost insignificant tasks. They map directly to an actual operation the CPU knows how to perform. The CPU uses only machine code. The instructions you type when programming assembly are memory aids so that you don’t need to remember machine code. For this reason, the words used for instructions (MOV, ADD, XOR, etc.) are often called mnemonics.
Assembly code consists of a list of these instructions one after the other, each on a new line. There are no compound instructions. In this way, assembly is very different from high-level languages where programmers are free to create complex conditional statements or mathematical expressions from simpler forms and parentheses. MASM is actually a high-level assembler, and complex statements can be formed by using its macro facilities, but that is not covered in detail in this book. In addition, MASM often allows mathematical expressions in place of constants, so long as the expressions evaluate to a constant (for instance, MOV AX, 5 is the same as MOV AX, 2+3).
Skeleton of an x64 Assembly File
The most basic native x64 assembly file of all would consist of just End written at the top of the file. This sample file is slightly more useful; it contains a .data and a .code segment, although no segments are actually necessary.
.data ; Define variables here .code ; Define procedures here End |
Skeleton of an x32 Assembly File
The skeleton of a basic 32-bit assembly file is slightly more verbose than the 64-bit version.
|
.xmm .model flat, c .data .code Function1 proc export push ebp mov ebp, esp ; Place your code here
pop ebp ret Function1 endp End |
The very first line describes the CPU the program is meant to run on. I have used .xmm, which means that the program requires a CPU with SSE instruction sets. This instruction set will be discussed in detail in Chapter 8). Almost all CPUs used nowadays have these instruction sets to some degree.
Note: Some other possible CPU values are .MMX, .586, .286. It is best to use the best possible CPU you wish your program to run on, since selecting an old CPU will enable backwards compatibility but at the expense of modern, powerful instruction sets.
I have included a procedure called Function1 in this skeleton. Sometimes the push, mov, and pop lines are not required, but I have included them here as a reminder that in 32-bit assembly, parameters are always passed on the stack and accessing them is very different in 32-bit assembly compared to 64-bit.
Comments
Anything to the right of a semicolon (;) is a comment. Comments can be placed on a line by themselves or they can be placed after an instruction.
; This is a comment on a line by itself mov eax, 24 ; This comment is after an instruction |
Note: It is a good idea to comment almost every line of assembly. Debugging uncommented assembly is extremely time consuming, even more so than uncommented high-level language code.
You can also use multiline or block comments with the comment directive shown in the sample code. The comment directive is followed by a single character; this character is selected by the programmer. MASM will treat all text until the next occurrence of this same character as a comment. Often the carat (^) or the tilde (~) characters are used, as they are uncommon in regular assembly code. Any character is fine as long as it does not appear within the text of the comment.
CalculateDistance proc comment ~ movapd xmm0, xmmword ptr [rcx] subpd xmm0, xmmword ptr [rdx] mulpd xmm0, xmm0 haddpd xmm0, xmm0 ~ sqrtpd xmm0, xmm0
ret CalculateDistance endp |
In the sample code, the comment directive appears with the tilde. This would comment out the four lines of code that are surrounded by the tilde. Only the final two lines would actually be assembled by MASM.
Destination and Source Operands
Throughout this reference, parameters to instructions will be called parameters, operands, or destination and source.
Destination: This is almost always the first operand; it is the operand to which the answer is written. In most two-operand instructions, the destination also acts as a source operand.
Source: This is almost always the second operand. The source of a computation can be either of the two operands, but in this book I have used the term source to exclusively mean the second parameter.
For instance, consider the following.
add rbx, rcx
RBX is the destination; it is the place that the answer is to be stored. RCX is the source; it is the value being added to the destination.
Segments
Assembly programs consist of a number of sections called segments; each segment is usually for a particular purpose. The code segment holds the instructions to be executed, which is the actual code for the CPU to run. The data segment holds the program's global data, variables, structure, and other data type definitions. Each segment resides in a different page in RAM when the program is executed.
In high-level languages, you can usually mix data and code together. Although this is possible in assembly, it is very messy and not recommended. Segments are usually defined by one of the following quick directives:
Table 1: Common Segment Directives
Directive | Segment | Characteristics |
.code | Code Segment | Read, Execute |
.data | Data Segment | Read, Write |
.const | Constant Data Segment | Read |
.data? | Uninitialized Data Segment | Read, Write |
Note: .code, .data, and the other segment directives mentioned in the previous table are predefined segment types. If you require more flexibility with your segment's characteristics, then look up the segment directive for MASM from Microsoft.
The constant data segment holds data that is read only. The uninitialized data segment holds data that is initialized to 0 (even if the data is defined as having some other value, it is set to 0). The uninitialized data segment is useful when a programmer does not care what value data should have when the application first starts.
Note: Instead of using the uninitialized data segment, it is also common to simply use a regular .data segment and initialize the data elements with “?”.
The characteristics column in the sample table indicates what can be done with the data in the segment. For instance, the code segment is read only and executable, whereas the data segment can be read and written.
Segments can be named by placing the name after the segment directive.
.code MainCodeSegment |
This is useful for defining sections of the same segment in different files, or mixing data and code together.
Note: Each segment becomes a part of the compiled .exe file. If you create a 5-MB array in your data segment your .exe will be 5 MB larger. The data defined in the data segment is not dynamic.
Labels
Labels are positions in the code segment to which the IP can jump using the JMP instructions.
[LabelName]:
Where [LabelName] is any valid variable name. To jump to a defined label you can use the JMP, Jcc (conditional jumps), or the CALL instruction.
SomeLabel: ; Some code jmp SomeLabel ; Immediately moves the IP to SomeLabel |
You can store a label in a register and jump to it indirectly. This is essentially using the register as a pointer to some spot in the code segment.
SomeLabel: mov rax, SomeLabel jmp rax ; Moves the IP to the address specified in RAX, SomeLabel |
Anonymous Labels
Sometimes it is not convenient to think of names for all the labels in a block of code. You can use the anonymous label syntax instead of naming labels. An anonymous label is specified by @@:. MASM will give it a unique name.
You can jump forward to an address higher than the current instruction pointer (IP) by using @F as the parameter to a JMP instruction. You can jump backwards to an address lower than the current IP by using @B as the parameter to a JMP instruction.
@@: ; An anonymous label jmp @F ; Instruction to jump forwards to the nearest anonymous label jmp @b ; Instruction to jump backwards to the nearest anonymous label |
Anonymous labels tend to become confusing and difficult to maintain, unless there is only a small number of them. It is usually better to define label names yourself.
Data Types
Most of the familiar fundamental data items from any high-level language are also inherent to assembly, but they all have different names.
The following table lists the data types referred to by assembly and C++. The sizes of the data types are extremely important in assembly because pointer arithmetic is not automatic. If you add 1 to an integer (dword) pointer it will move to the next byte, not the next integer as in C++.
Some of the data types do not have standardized names; for example, the XMM word and the REAL10 are just groups of 128 bits and 80 bits. They are referred to as XMM words or REAL10 in this book, despite that not being their name but a description of their size.
Some of the data types in the ASM column have a short version in parentheses. When defining data in the data segment, you can use either the long name or the short one. The short names are abbreviations. For example, "define byte" becomes “db”.
Note: Throughout this book, I will always refer to double words as dwords, and double-precision floats as doubles.
Table 2: Fundamental Data Types
Type | ASM | C++ | Bits | Bytes |
|---|---|---|---|---|
Byte | byte (db) | char | 8 | 1 |
Signed byte | sbyte | char | 8 | 1 |
Word | word (dw) | unsigned short | 16 | 2 |
Signed word | sword | short | 16 | 2 |
Double word | dword (dd) | unsigned int | 32 | 4 |
Signed double word | sdword | int | 32 | 4 |
Quad word | qword (dq) | unsigned long long | 64 | 8 |
Signed quad word | sqword | long long | 64 | 8 |
XMM word (dqword) | xmmword | 128 | 16 | |
YMM word | ymmword | 128 | 16 | |
Single | real4 | float | 32 | 4 |
Double | real8 | double | 64 | 8 |
Ten byte float | real10 (tbyte, dt) | 80 | 10 |
Data is usually drawn with the most significant bit to the left and the least significant to the right. There is no real direction in memory, but this book will refer to data in this manner. All data types are a collection of bytes, and all data types except the REAL10 occupy a number of bytes that is some power of two.
There is no difference between data types of the same size to the CPU. A REAL4 is exactly the same as a dword; both are simply 4-byte chunks of RAM. The CPU can treat a 4-byte block of code as a REAL4, and then treat the same block as a dword in the very next instruction. It is the instructions that define whether the CPU is to use a particular chunk of RAM as a dword or a REAL4. The variable types are not defined for the CPU; they are defined for the programmer. It is best to define data correctly in your data segment because Visual Studio's debugging windows display data as signed or unsigned and integer or floating point based on their declarations.
There are several data types which have no native equivalent in C++. The XMM and YMM word types are for Single Instruction Multiple Data (SIMD), and the rather oddball REAL10 is from the old x87 floating point unit.
Note: This book will not cover the x87 floating point unit's instructions, but it is worth noting that this unit, although legacy, is actually capable of performing tasks the modern SSE instructions cannot. The REAL10 type adds a large degree of precision to floating point calculations by using an additional 2 bytes of precision above a C++ double.
Little and Big Endian
x86 and x64 processors use little endian (as opposed to big endian) byte order to represent data. So the byte at the lowest address of a multiple byte data type (words, dwords, etc.) is the least significant, and the byte at the highest address is the most significant. Imagine RAM as a single long array of bytes from left to right.
If there is a word or 2-byte integer at some address (let us use 0x00f08480, although in reality a quad word would be used to store this pointer so it would be twice as long) with the values 153 in the upper byte and 34 in the lower, then the 34 would be at the exact address of the word (0x00f08480). The upper byte would have 153 and would be at the next byte address (0x00f08481), one byte higher. The number the word is storing in this example is the combination of these bytes as a base 256 number (34+153×256).
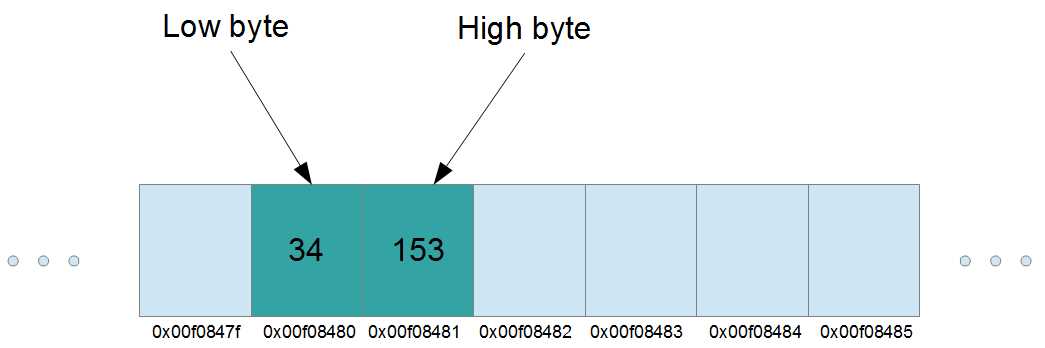
Figure 11
This word would actually be holding the integer 39,202. It can be thought of as a number in base 256 where the 34 is the first digit and the 153 is the second, or 39202 = 34+153×(256^1).
Two’s and One’s Complement
In addition to being little endian, x86 and x64 processors use two’s complement to represent signed, negative numbers. In this system, the most significant bit (usually drawn as the leftmost) is the sign bit. When this bit is 0, the number being represented is positive and when this bit is 1, the number is negative. In addition, when a number is negative, the number it represents is the same as flipping all the bits and adding 1 to this result. So for example, the bit pattern 10110101 in a signed byte is negative since the left bit is 1. To find the actual value of the number, flip all the bits and add 1.
Flipping each bit of 10110101 gives you 01001010.
01001010 + 1 = 01001011
01001011 in binary is the number 75 in decimal.
So the bit pattern 10110101 in a signed byte on a system that represents signed numbers with two's complement is representing the value -75.
Note: Flipping the bits is called the one's complement, bitwise complement, or the complement. Flipping the bits and adding one is called the two's complement or the negative. Computers use two's complement, as it enables the same circuitry used for addition to be used for subtraction. Using two's complement means there is a single representation of 0 instead of -0 and +0.
DISCLAIMER: Web reader is currently in beta. Please report any issues through our support system. PDF and Kindle format files are also available for download.
1. Assembly in Visual Studio
2. Fundamentals
3. Memory Spaces
4. Addressing Modes
5. Data Segment
6. C Calling Convention
7. Instruction Reference
8. SIMD Instruction Sets
- 1800+ high-performance UI components.
- Includes popular controls such as Grid, Chart, Scheduler, and more.
- 24x5 unlimited support by developers.