

LINQ is a powerful querying tool for .NET applications. There are certain techniques to follow when writing queries to make sure they run quickly and effectively. The following are a few things to consider when aiming to improve the performance of LINQ to Entities:
- Pull only the needed columns
- Use of IQueryable and Skip/Take
- Use of left join and inner join at the right places
- Use of AsNoTracking()
- Bulk data insert
- Use of async operations in entities
- Look for parameter mismatches
- Check SQL query submitted to database
1. Pull only the needed columns
When working with LINQ, only pull the needed columns in the Select clause instead of loading all the columns in the table.
Consider the following LINQ query.
using (var context = new LINQEntities())
{
var fileCollection = context.FileRepository.Where(a => a.IsDeleted == false).ToList();
}
This query will be compiled into SQL as shown the following screenshot.
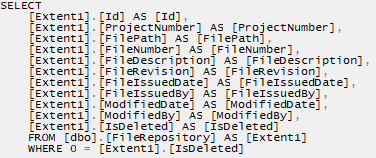
Though we might need only a few columns, we have loaded them all. This consumes more memory than necessary and slows down query execution. We can change the query as follows for better execution.
using (var context = new LINQEntities())
{
var fileCollection = context.FileRepository.Where(a => a.IsDeleted == false).
Select(a => new
{
FilePath = a.FilePath
}
).ToList();
}
This query will be compiled into SQL in an optimized way, as shown in the following screenshot.

2. Use of IQueryable and Skip/Take
When working with a large collection of data and binding it with a table or grid control, we should not load all records for the user in a single instance because it takes a long time.
Instead, we can load a certain number of records initially, say 10 or 20. When the user wants to see the next set of records, we can load the next 10 or 20 records on demand.
The IQueryable type in C# can hold unevaluated SQL queries, which can later be converted to run against the data collection after applying skip and take.
C#
private IEnumerable<object> LoadAllFiles(int skip, int take,string fileRevision,string fileNumber)
{
using (var context = new LINQEntities())
{
//Select and perform join on the needed tables and build an IQueryable collection
IQueryable<FileRepository> fileCollection = context.FileRepository;
//Build queries dynamically over Queryable collection
if(!string.IsNullOrEmpty(fileRevision))
fileCollection = fileCollection.Where(a => a.FileRevision == fileRevision && a.IsDeleted == false);
//Build queries dynamically over Queryable collection
if (!string.IsNullOrEmpty(fileNumber))
fileCollection = fileCollection.Where(a => a.FileRevision == fileNumber && a.IsDeleted == false);
//Apply skip and take and load records
return fileCollection.OrderBy(a=>a.Id).Skip(skip).Take(take).Select(a=>new
{
FileIssuedBy=a.FileIssuedBy
}).ToList();
}
}
SQL
exec sp_executesql N'SELECT
[Project1].[C1] as [C1],
[Project1].[FileIssuedBy] as [FileIssuedBy],
FROM (SELECT
[Extent1].[Id] as [Id],
[Extent1].[FileIssuedBy] as [FileIssuedBy],
1 as [C1]
FROM [dbo].[FileRepository] as [Extent1]
WHERE ([Extent1].[FileRevision] = @p_linq_0) AND (0=[Extent1].[IsDeleted]) AND ([Extent1].[FileRevision] = @p_linq_1)
AND (0=[Extent1].[IsDeleted])) AS [Project1]
ORDER BY row_number() OVER (ORDER BY [Project1].[Id] ASC)
OFFSET @p_linq_2 ROWS FETCH NEXT @p_linq_3 ROWS ONLY ',N'@p_linq_0 nvarchar(4000),@p_linq_1 nvarchar(4000),
@p_linq_2 int,@p_linq_3
int',@p_linq_0=N'A',@p_linq_1=N'A',@p_pinq_2=0,@p_linq_3=10
3. Use of left join and inner join at the right places
Where left join and inner join are applied also play a vital role in query execution. When we are not sure whether the records in Table A will have matching records in Table B, we should use left join. When we are certain that there will be relational records in both tables, we should use inner join.
Choosing the right type of join for establishing a relation between tables is important, as multiple tables with inner join queries execute better than multiple tables with left joins.
Hence, we should identify our requirements and use join (left or inner) for better query execution.
4. Use of AsNoTracking()
When we load records from a database via LINQ-to-Entities queries, we will be processing them and update them back to the database. For this purpose, entities be tracked.
When we are performing only read operations, we won’t make any updates back to the database, but entities will assume that we are going to make updates back to the database and will process them accordingly. So, we can use AsNoTracking() to restrict entities from assuming and processing, thus reducing the amount of memory that entities will track.
using (var context = new LINQEntities())
{
var fileCollection = context.FileRepository.AsNoTracking().Where(a => a.IsDeleted == false).
Select(a => new
{
FilePath = a.FilePath
}
).ToList();
}
5. Bulk data insert
Another situation to consider is when working with bulk data inserts, such as adding hundreds or thousands of records to a SQL table.
using (var context = new LINQEntities())
{
for(int i=1;i<=1000;i++)
{
var file = new FileRepository { FilePath=""+i+"",FileDescription=""+i+""};
context.FileRepository.Add(file);
}
context.SaveChanges();
}
Each time we add a new entity to FilesRepository in the previous code sample, DetectChanges() from Data.Entity.Core will be triggered, and query execution will become slower.
To overcome this, use AddRange, which best suits bulk inserts. AddRange was introduced in EF 6.0 for doing insertions in a single database round trip to reduce the performance overhead. Take a look at the following modified code.
using (var context = new LINQEntities())
{
var fileCollection = new List<FileRepository>();
for(int i=1;i<=1000;i++)
{
var file = new FileRepository { FilePath=""+i+"",FileDescription=""+i+""};
fileCollection.Add(file);
}
context.FileRepository.AddRange(fileCollection);
context.SaveChanges();
}
6. Use of async operations in entities
Entities offer the following async operations:
- ToListAsync(): Retrieves collection of data asynchronously.
- CountAsync(): Retrieves data count asynchronously.
- FirstAsync(): Retrieves first data set asynchronously.
- SaveChangesAsync(): Saves the entity changes asynchronously.
Async operations are used at specific places in applications to reduce the blocking of the UI thread. They enhance the UI by making it responsive.
using (var context = new LINQEntities())
{
var countAsync = context.FileRepository.CountAsync();
var listAsync = context.FileRepository.ToListAsync();
var firstAsync = context.FileRepository.FirstAsync();
context.SaveChangesAsync();
}
7. Look for parameter mismatch
Data types may not match when querying, which often leads to significant time consumption when using LINQ to Entities. Consider a scenario where we have a column, FileNumber, in a table, which is of type varchar and holds 10 characters. Hence, it was declared as varchar(10) data type.
We need to load records that the FileNumber field values match in “File1”.
using (var context = new LINQEntities())
{
string fileNumber = "File1";
var fileCollection = context.FileRepository.Where(a => a.FileNumber == fileNumber).ToList();
}
SQL

In the highlighted section in the previous screenshot, we can see that the variable we passed has been declared in SQL as nvarchar(4000), whereas in the table column, we have the column type as varchar(10). So, there will be a conversion that the SQL will perform internally as there is a parameter type mismatch.
To overcome this parameter mismatch, we need to mention the type of column with the property name, as in the following code.
public string FilePath { get; set; }
[Column(TypeName = "varchar")]
public string FileNumber { get; set; }
Now, the SQL parameter type will be generated as varchar.
8. Check the SQL query submitted to the database
Checking a SQL query before submitting it to a database is the most important thing you can do when trying to improve the performance of a LINQ-to-Entities query. We all know that the LINQ-to-Entities query will be converted to an SQL query and will be executed against a database. A SQL query that is generated as a result of a LINQ query will be effective for better performance.
Let’s see an example. Consider the query that follows, which uses navigational LINQ between Room, RoomProducts, and Brands.
Assume the following:
- The Room table will hold a list of rooms for a hotel.
- The RoomProducts table will hold a list of products in Room, and refers to Room.Id as a foreign key.
- The Brands table will hold the RoomProducts brands and will refer to RoomProducts.Id as a foreign key.
- The records in all three tables will definitely have a relational record in them.
Let me write a LINQ query that maps all tables with join and pulls the matching records.
C#
using (var context = new LINQEntities())
{
var roomCollection = context.Rooms.
Include(x => x.RoomProducts).Select
(x => x.RoomProducts.Select(a => a.Brands)).
ToList();
}
We are getting Room, RoomProducts, and Brands collections. The query’s equivalent SQL is presented in the following code.
SQL
SELECT
[Project1].[Id] AS [Id],
[Project1].[C2] AS [C1],
[Project1].[Id1] AS [Id1],
[Project1].[C1] AS [C2],
[Project1].[Id2] AS [Id2],
[Project1].[Brand] AS [Brand],
[Project1].[RoomProductsParentId] AS [RoomProductsParentId],
[Project1].[IsDeleted] AS [IsDeleted],
[Project1].[ModifiedDate] AS [ModifiedDate],
[Project1].[ModifiedBy] AS [ModifiedBy]
FROM ( SELECT
[Extent1].[Id] AS [Id],
[Join1].[Id1] AS [Id1],
[Join1].[Id2] AS [Id2],
[Join1].[Brand] AS [Brand],
[Join1].[RoomProductsParentId] AS [RoomProductsParentId],
[Join1].[IsDeleted1] AS [IsDeleted],
[Join1].[ModifiedDate1] AS [ModifiedDate],
[Join1].[ModifiedBy1] AS [ModifiedBy],
CASE WHEN ([Join1].[Id1] IS NULL) THEN CAST(NULL AS int) WHEN ([Join1].[Id2] IS NULL) THEN CAST(NULL AS int) ELSE 1 END AS [C1],
CASE WHEN ([Join1].[Id1] IS NULL) THEN CAST(NULL AS int) ELSE 1 END AS [C2]
FROM [dbo].[Rooms] AS [Extent1]
LEFT OUTER JOIN (SELECT [Extent2].[Id] AS [Id1], [Extent2].[RoomParentId] AS [RoomParentId], [Extent3].[Id] AS [Id2], [Extent3].[Brand] AS [Brand], [Extent3].[RoomProductsParentId] AS [RoomProductsParentId], [Extent3].[IsDeleted] AS [IsDeleted1], [Extent3].[ModifiedDate] AS [ModifiedDate1], [Extent3].[ModifiedBy] AS [ModifiedBy1]
FROM [dbo].[RoomProducts] AS [Extent2]
LEFT OUTER JOIN [dbo].[Brands] AS [Extent3] ON [Extent2].[Id] = [Extent3].[RoomProductsParentId] ) AS [Join1] ON [Extent1].[Id] = [Join1].[RoomParentId]
) AS [Project1]
ORDER BY [Project1].[Id] ASC, [Project1].[C2] ASC, [Project1].[Id1] ASC, [Project1].[C1] ASC
We can see that the query generated as part of the navigation property uses a left-outer join for establishing a relation between the tables and loads all columns. The queries formed by the left-outer join run slower when compared with inner-join queries.
Since we know that all three tables will definitely have a relation in them, let us modify this query slightly.
C#
using (var context = new LINQEntities())
{
var roomCollection = (from room in context.Rooms
join products in context.RoomProducts on room.Id equals products.RoomParentId
join brands in context.Brands on products.Id equals brands.RoomProductsParentId
select new
{
Room = room.Room,
Product = products.RoomProduct,
Brand = brands.Brand
}).ToList();
}
This produces the following:
SQL
SELECT
[Extent1].[Id] AS [Id],
[Extent1].[Room] AS [Room],
[Extent2].[RoomProduct] AS [RoomProduct],
[Extent3].[Brand] AS [Brand]
FROM [dbo].[Rooms] AS [Extent1]
INNER JOIN [dbo].[RoomProducts] AS [Extent2] ON [Extent1].[Id] = [Extent2].[RoomParentId]
INNER JOIN [dbo].[Brands] AS [Extent3] ON [Extent2].[Id] = [Extent3].[RoomProductsParentId]
Now, the code looks cleaner and executes faster than our previous attempt.
Conclusion
In this blog, we have seen some of the areas where we can concentrate on improving the performance of LINQ to Entities. We hope you find this article helpful.
Syncfusion provides a wide range of controls to ease the work of developers on various platforms. Please have a look and use them in your application development:
- ASP.NET Core
- ASP.NET MVC
- Angular
- Blazor
- React
- Vue
- JavaScript
- Flutter
- Xamarin
- WPF
- WinForms
- WinUI
- .NET MAUI
If you have any questions or require clarifications about our components, please let us know in the comments below. You can also contact us through our support forum, support portal, or feedback portal. We are happy to assist you!
 No spam, just valuable updates.
No spam, just valuable updates.
Comments (10)
Thanks for this blog post. Very helpful.
Hi DIWAS POUDEL,
Thank you. It motivates us to create more useful blogs.
Thanks,
Selvam M
Nice blog.
Hi KINJAL,
Thank you. It motivates us to create more useful blogs.
Thanks,
Selvam M
Helped me a lot, thank u sir
Hi JACOB,
Thank you. It motivates us to create more useful blogs.
Thanks,
Selvam M
Very didactic and helpful.
Hi VICTOR,
Thank you. It motivates us to create more useful blogs.
Thanks,
Selvam M
I am using repository pattern, is it good to use select to limit the columns for property domain while in actual property domain have more than 100 fields
public async Task<IEnumerable> GetPropertiesAsync()
{
var properties = await dc.Properties
.Include(p => p.PropertyType)
.Include(p => p.City)
.Include(p => p.FurnishType)
.Where(p => p.SellRent == sellRent)
.Select(p => new Property {
Id = p.Id,
Name = p.Name,
PropertyType = p.PropertyType,
FurnishType = p.FurnishType,
Price = p.Price,
BHK = p.BHK,
BuiltArea = p.BuiltArea,
City= p.City,
ReadyToMove = p.ReadyToMove
})
.ToListAsync();
return properties;
}
Hi Sandeep,
Yes we can use. To confirm it you can see the SQL query generated against above query that we are pulling selective fields.
Thanks,
Selvam M