

The Syncfusion PDF Library is a .NET library that allows users to extract various types of useful data from a PDF document, such as text, images, attachments, and form data, using C# and VB.NET.
PDF documents are mostly used for exchanging business data in the form of invoices, purchase orders, shipping notes, reports, presentations, price and product lists, HR forms, and more.
In certain scenarios, a user must read and validate the data present in a PDF document, which imposes additional costs and time requirements to do manually. To avoid this, we can use text extraction to pull all the data, or only some of it, from a PDF document, and then validate it further in an automated way.
In this blog, we are going to focus on the following nine types of data extraction from PDF documents:
- Extract all text from a PDF document.
- Extract text from predefined bounds.
- Extract text based on layout.
- Extract text from a scanned PDF document.
- Extract images from a PDF.
- Find invoice total amount in a PDF with regex.
- Extract PDF document information.
- Extract attachments from a PDF.
- Extract filled PDF form data and save as XML.
Extract all text from PDF document
Important data elements in PDF files (e.g., order number, date, total, and other fields in an invoice) have to be extracted to gain insight about the information in the files. So, huge volumes of PDF documents need manual processing to find the information, which requires a huge workforce. This can be avoided by automating with text extraction methods.
With the Syncfusion PDF library, you can extract all the text from a PDF document or from a specific page of the document.
The following code example explains the procedure to extract text from a specific page.
//Load the PDF document
PdfLoadedDocument loadedDocument = new PdfLoadedDocument("../../Data/Invoice.pdf");
// Get the first page of the loaded PDF document
PdfPageBase page = loadedDocument.Pages[0];
// Extract text from the first page with bounds
string extractedText = page.ExtractText();
loadedDocument.Close(true);
File.WriteAllText("data.txt", extractedText);
The following code example explains the procedure to extract all text from the entire PDF document.
FileStream inputStream = new FileStream("Invoice.pdf",FileMode.Open);
//Load the PDF document
PdfLoadedDocument loadedDocument = new PdfLoadedDocument(inputStream);
StringBuilder extractedText = new StringBuilder();
// Extract all the text from the PDF document pages
foreach (PdfLoadedPage loadedPage in loadedDocument.Pages)
{
extractedText.Append(loadedPage.ExtractText());
}
//Close the document
loadedDocument.Close(true);
//Save the text to file
File.WriteAllText("data.txt", extractedText.ToString());
Extract text from predefined bounds
Sometimes we don’t need all the text extracted from a PDF document, such as when we only need to validate some specific information (e.g., the invoice number from an invoice). For this scenario, we need to pick specific text from declared bounds within a PDF document.
To do this, we need to specify bounds where the key data is present in the PDF document.
The following code example illustrates the procedure to extract text from the specified bounds.
//Load the PDF document
PdfLoadedDocument loadedDocument = new PdfLoadedDocument("Invoice.pdf");
// Get the first page of the loaded PDF document
PdfPageBase page = loadedDocument.Pages[0];
TextLines lineCollection = new TextLines();
// Extract text from the first page with bounds
page.ExtractText(out lineCollection);
RectangleF textBounds = new RectangleF(474, 161, 50, 9);
string invoiceNumer = "";
//Get the text provided in the bounds
foreach (TextLine txtLine in lineCollection)
{
foreach (TextWord word in txtLine.WordCollection)
{
if (textBounds.IntersectsWith(word.Bounds))
{
invoiceNumer = word.Text;
break;
}
}
}
loadedDocument.Close(true);
File.WriteAllText("data.txt", invoiceNumer);
By executing this code example, you will get a text document like the one in the following screenshot.
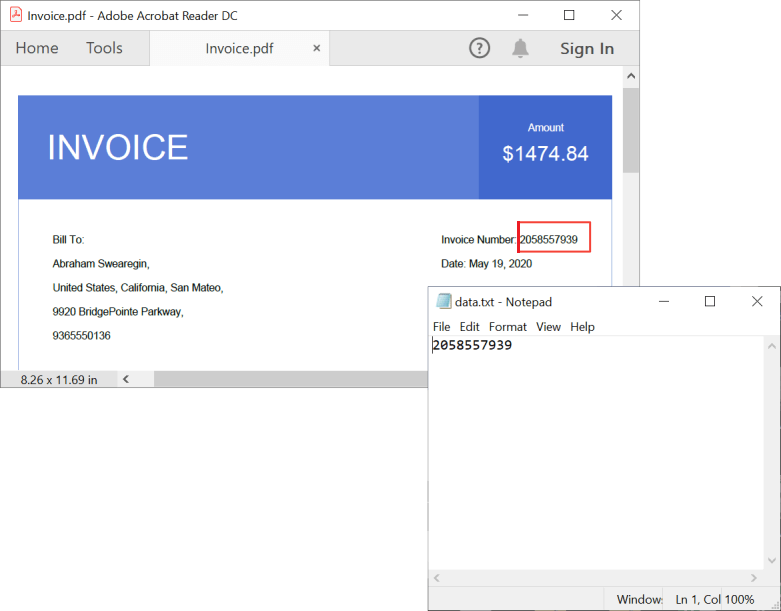
Layout-based text extraction
When PDF documents don’t have a common layout structure, it is difficult to extract their text in a way that approximates the original layout of the document. Layout-based text extraction provides a clear view of the text data in a form that resembles the original document layout.
With the Syncfusion PDF library, you can extract text from the given PDF page based on its layout by using the ExtractText(bool) overload method.
The following code illustrates how to extract text based on the layout of the document.
//Load the PDF document
PdfLoadedDocument loadedDocument = new PdfLoadedDocument("Invoice.pdf");
//Get the first page of the loaded PDF document
PdfPageBase page = loadedDocument.Pages[0];
//Extract text with layout
string extractedText = page.ExtractText(true);
//Save text to file
File.WriteAllText("data.txt", extractedText);
//Close the PDF document
loadedDocument.Close(true);
By executing this code example, you will get a text document like the one in the following screenshot.
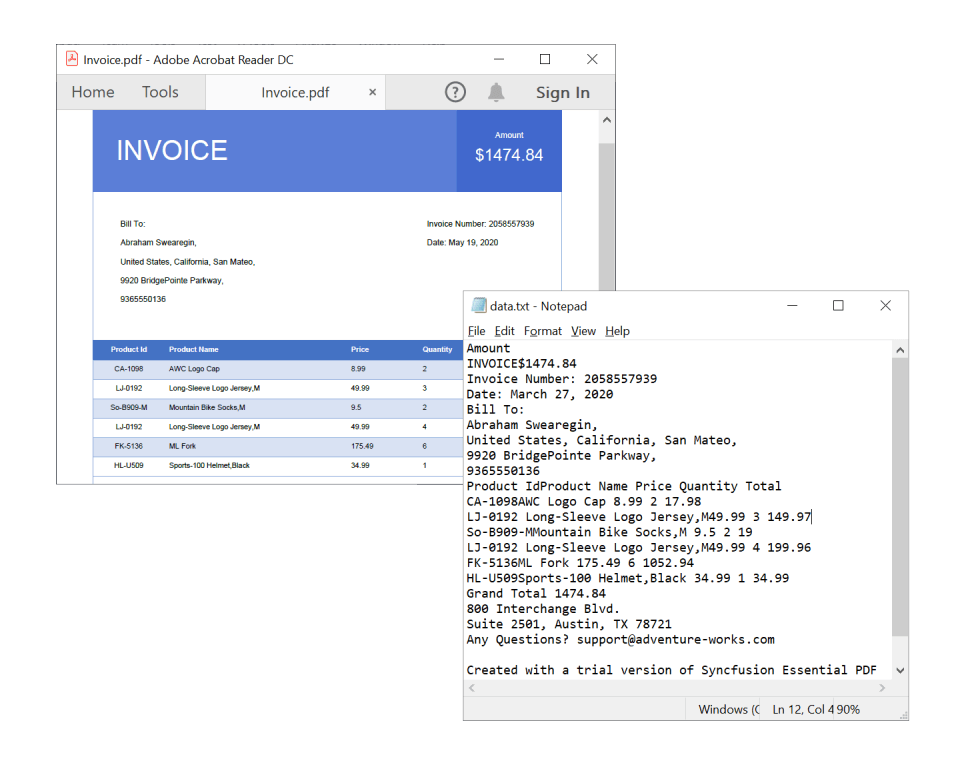
Extract text from a scanned PDF document
When PDF documents are created from scanned image files, we cannot use our usual text extraction methods. We must turn to OCR processing to extract the text from the PDF document.
The Syncfusion OCR Processor library has the functionalities to perform OCR processing on PDF documents. You can find more details in this documentation.
The Syncfusion OCR NuGet packages are available at the following links:
The following code example illustrates how to extract text from a PDF document generated from a scanned image.
//Initialize OCR processor
OCRProcessor processor = new OCRProcessor(@"../../TesseractBinaries/3.02/");
//Load a PDF document
PdfLoadedDocument lDoc = new PdfLoadedDocument("../../Data/Invoice.pdf");
//Set OCR language to process
processor.Settings.Language = Languages.English;
OCRLayoutResult hocrBounds;
processor.PerformOCR(lDoc, @"../../Tessdata/", out hocrBounds);
StreamWriter writer = new StreamWriter("data.txt");
foreach(Page pages in hocrBounds.Pages)
{
foreach(Line line in pages.Lines)
{
writer.WriteLine(line.Text);
}
}
writer.Close();
lDoc.Close(true);
processor.Dispose();
By executing this code example, you will get a text document like the one in the following screenshot.

Extract images from PDF
The extract images feature allows you to extract and reuse images in any other applications or PDF documents.
The following code example illustrates the procedure to extract images from the PDF document.
// Load an existing PDF
PdfLoadedDocument loadedDocument = new PdfLoadedDocument("../../../../../../Data/Template.pdf");
foreach(PdfPageBase page in loadedDocument.Pages)
{
//Extract images from first page
Image[] extractedImages=page.ExtractImages();
foreach(Image image in extractedImages)
{
//Save each image to file
image.Save(Guid.NewGuid().ToString() + ".jpg",ImageFormat.Jpeg);
}
}
//Close the document
loadedDocument.Close(true);
By executing this code example, you will get the image like in the following screenshot.
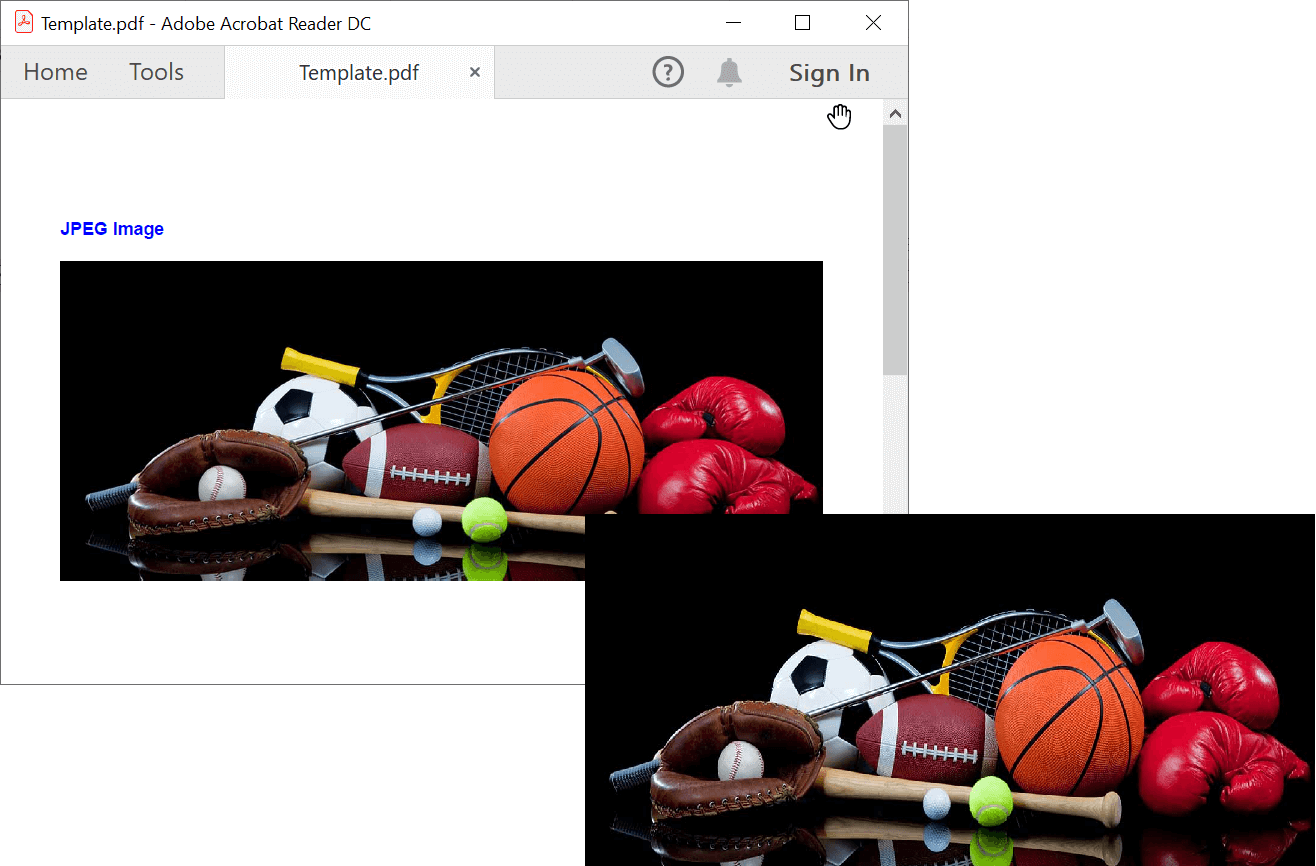
Note: Use the following NuGet link for the package needed to extract images from PDF documents on the .NET Core platform:https://www.nuget.org/packages/Syncfusion.Pdf.Imaging.Net.Core/.
Find invoice total amount in PDF with regex
Sometimes in a PDF document, we might need only a single piece of data, such as the total amount in an invoice. In this case, we can use regex (regular expressions) to get the data with the highest value.
The following code example illustrates the procedure to extract the required text data from the PDF document using regex.
//Load the PDF document
PdfLoadedDocument loadedDocument = new PdfLoadedDocument("../../../../../../Data/Invoice.pdf");
//Search for total amount
string regexPattern = @"(TOTAL)([-+]?[0-9]*\.?[0-9]+)";
// See the complete regular expressions reference at https://msdn.microsoft.com/en-us/library/az24scfc(v=vs.110).aspx
// Extract all the text from existing PDF document pages
foreach (PdfLoadedPage loadedPage in loadedDocument.Pages)
{
TextLines lines;
loadedPage.ExtractText(out lines);
foreach(TextLine line in lines)
{
Regex re = new Regex(regexPattern, RegexOptions.IgnoreCase);
Match match = re.Match(line.Text);
if (match.Success)
{
//Print the total amount
Console.WriteLine("Found Total Amount Number:" + match.Value.Replace("Total", ""));
}
}
}
//Close the document
loadedDocument.Close(true);
By executing this code example, you will get the text output like in the following screenshot.
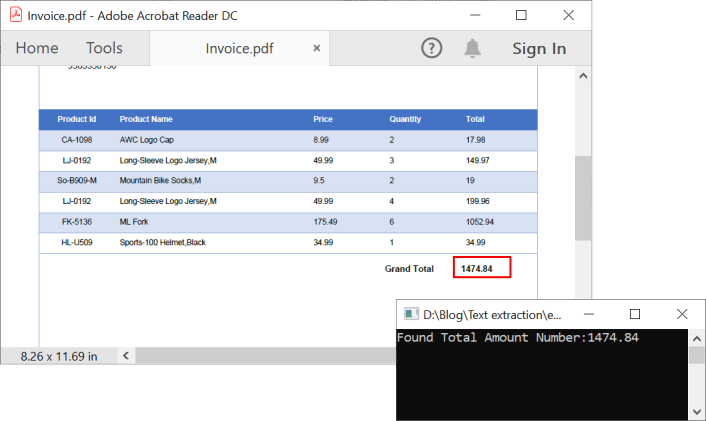
Extract PDF document information
Let’s see how to extract a document’s information, such as author, creator, producer, and more.
The following code example illustrates the procedure to extract a PDF document’s information.
//Load the PDF document
PdfLoadedDocument loadedDocument = new PdfLoadedDocument("../../../../../../Data/Invoice.pdf");
//Get all the document information
Console.WriteLine("Author: " + loadedDocument.DocumentInformation.Author);
Console.WriteLine("Creator: " + loadedDocument.DocumentInformation.Creator);
Console.WriteLine("Producer: " + loadedDocument.DocumentInformation.Producer);
Console.WriteLine("Subject: " + loadedDocument.DocumentInformation.Subject);
Console.WriteLine("Title: " + loadedDocument.DocumentInformation.Title);
Console.WriteLine("CreationDate: " + loadedDocument.DocumentInformation.CreationDate);
Console.WriteLine("Keywords: " + loadedDocument.DocumentInformation.Keywords);
Console.WriteLine("Encrypted: " + loadedDocument.IsEncrypted);
//Close the document
loadedDocument.Close(true);
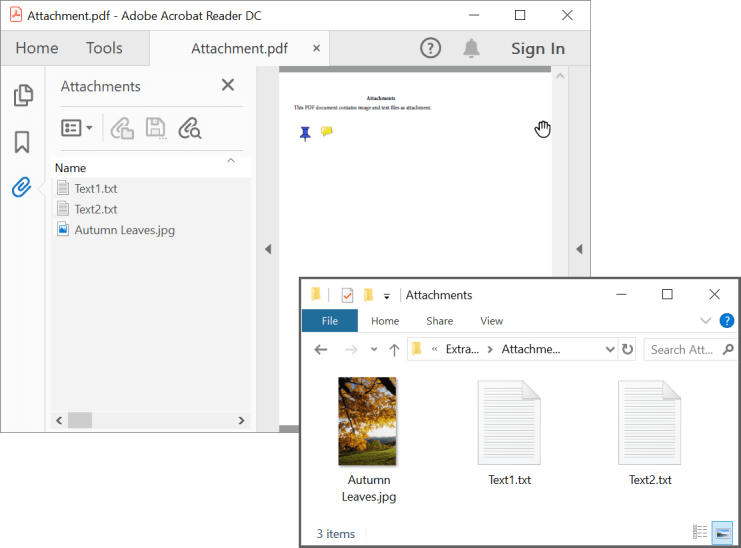
Extract attachments from PDF
PDF attachments may be different kinds of documents, such as Word documents, Excel worksheets, PowerPoint presentations, images, and more, and they might contain important data. You can extract these attachments from an existing PDF document using the following code example.
//Load the PDF document
PdfLoadedDocument loadedDocument = new PdfLoadedDocument("../../../../../../Data/Attachment.pdf");
//Get first page from document
PdfLoadedPage page = loadedDocument.Pages[0] as PdfLoadedPage;
//Get the annotation collection from pages
PdfLoadedAnnotationCollection annotations = page.Annotations;
//Iterates the annotations
foreach (PdfLoadedAnnotation annot in annotations)
{
//Check for the attachment annotation
if (annot is PdfLoadedAttachmentAnnotation)
{
PdfLoadedAttachmentAnnotation file = annot as PdfLoadedAttachmentAnnotation;
//Extracts the attachment and saves it to the disk
FileStream stream = new FileStream(file.FileName, FileMode.Create);
stream.Write(file.Data, 0, file.Data.Length);
stream.Dispose();
}
}
//Iterates through the attachments
if (loadedDocument.Attachments.Count != 0)
{
foreach (PdfAttachment attachment in loadedDocument.Attachments)
{
//Extracts the attachment and saves it to the disk
FileStream stream = new FileStream(attachment.FileName, FileMode.Create);
stream.Write(attachment.Data, 0, attachment.Data.Length);
stream.Dispose();
}
}
//Close the document
loadedDocument.Close(true);
By executing this code example, you will get the output like in the following screenshot.
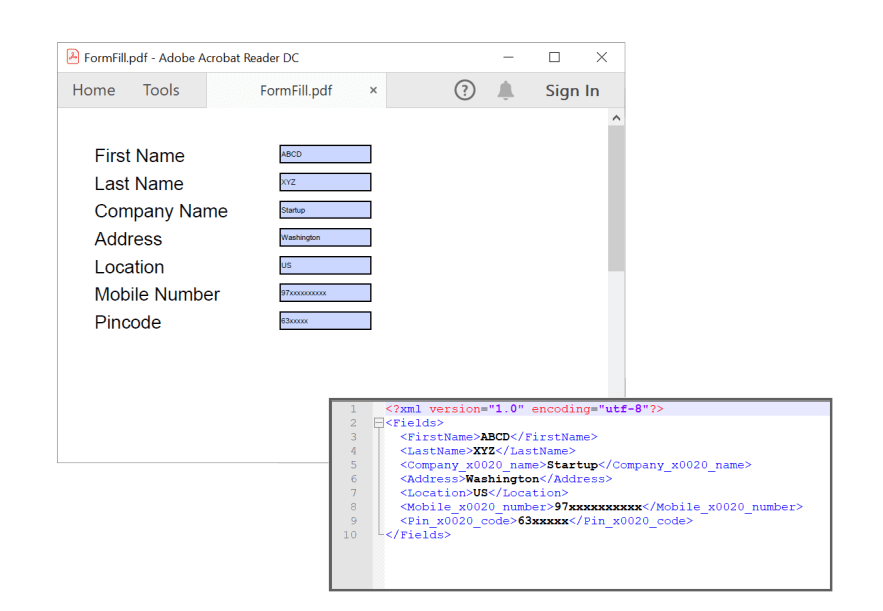
Extract filled PDF form data and save it as XML
A PDF document can be used as a form to acquire details from users in an interactive way. For instance, form fields in a PDF document could be used to acquire attendee data for an event registration, but correlating the provided data would be hectic.
In this situation, you can extract the filled data and save it as XML using the ExportData method.
The following code example illustrates the procedure to export filled PDF form data to an XML file.
PdfLoadedDocument loadedDocument = new PdfLoadedDocument(@"../../../../../../Data/FormFill.pdf");
//Load an existing form
PdfLoadedForm loadedForm = loadedDocument.Form;
//Export the existing PDF form data to an XML file
loadedForm.ExportData("Export.xml", DataFormat.Xml, @"AcroForm1");
//Close the document
loadedDocument.Close(true);
By executing this code example, you will get the output like in the following screenshot.
Resources
The project samples to perform all these extraction operations are available in this GitHub repository.
Conclusion
In this blog post, we have learned various ways to extract data from a PDF document. Take a moment to peruse our documentation, where you’ll find other operations that can be performed over PDF documents. Every feature is accompanied by code examples.
If you have any questions about these features, please let us know in the comments section below. You can also contact us through our support forum, Support Portal, or feedback portal. We are happy to assist you!
If you like this article, we think you will also like the following articles about the Syncfusion PDF Library:
 No spam, just valuable updates.
No spam, just valuable updates.
Comments (1)
Hello
I want to extract a table from a pdf and turn it into a list to save it in a database table, is it possible to do this? And if so, will you have an example?