

Syncfusion Flutter PDF library is a file-format library that allows you to add robust PDF functionalities to your Flutter applications. With it, you can create PDF reports programmatically with formatted text, images, tables, links, lists, headers and footers, bookmarks, and more. This library also offers functionalities to read and edit PDF documents without Adobe dependencies.
PDF documents are mostly used for exchanging business data in the form of invoices, purchase orders, shipping notes, reports, presentations, price and product lists, HR forms, and more.
At some point, a user might need to read and validate the data present in a PDF document. This may require some additional cost and time to do this manually. To avoid this problem, we can use text extraction techniques. These techniques will extract all the text data or specific text data from a PDF document to validate further in an automated way.
By using our Flutter PDF library, you can easily extract text from a PDF document in your Flutter application. In this blog, we are going to cover how to do the following:
- Extract all the text from a PDF document.
- Extract text from predefined bounds.
- Extract text from a specific page.
- Extract text from a range of pages.
- Extract text with font and style information.
And we’ll provide code examples along the way!
Extract all the text from a PDF document
With the Syncfusion Flutter PDF library, you can extract all the text from a PDF document. Here’s the procedure to do so:
Step 1: Create a Flutter application
Follow the instructions provided in this Getting Started documentation to create a basic Flutter application.
Step #2: Add the Syncfusion Flutter PDF dependency
Include the Syncfusion Flutter PDF package dependency in the pubspec.yaml file in your project. Refer to the following code.
dependencies: syncfusion_flutter_pdf: ^18.3.53-beta
Step #3: Get the package
Run the following command to get the required package.
$ flutter pub get |
Step #4: Import the package
Import the PDF package into your main.dart file using the following code example.
import 'package:syncfusion_flutter_pdf/pdf.dart';
Step #5: Extract all the text from the PDF document
- Add a button widget as a child to your container widget as shown in the following code example.
@override Widget build(BuildContext context) { return Scaffold( appBar: AppBar( title: Text(widget.title), ), body: Center( child: Column( mainAxisAlignment: MainAxisAlignment.center, children: <Widget>[ FlatButton( child: Text( 'Generate PDF', style: TextStyle(color: Colors.white), ), onPressed: _extractText, color: Colors.blue, ) ], ), ), ); } - Include the following code in the button click event to extract all the text from the entire PDF file.
//Load an existing PDF document. PdfDocument document = PdfDocument(inputBytes: await _readDocumentData('pdf_succinctly.pdf')); //Create a new instance of the PdfTextExtractor. PdfTextExtractor extractor = PdfTextExtractor(document); //Extract all the text from the document. String text = extractor.extractText(); //Display the text. _showResult(text); - Include the following code to read the PDF document from the folder where it is saved. Here, we have named our folder assets.
Future<List<int>> _readDocumentData(String name) async { final ByteData data = await rootBundle.load('assets/$name'); return data.buffer.asUint8List(data.offsetInBytes, data.lengthInBytes); } - Include the following code to display the extracted text.
void _showResult(String text) { showDialog( context: context, builder: (BuildContext context) { return AlertDialog( title: Text('Extracted text'), content: Scrollbar( child: SingleChildScrollView( child: Text(text), physics: BouncingScrollPhysics( parent: AlwaysScrollableScrollPhysics()), ), ), actions: [ FlatButton( child: Text('Close'), onPressed: () { Navigator.of(context).pop(); }, ) ], ); }); }
By executing the previous code example, the text extracted from the PDF document will be displayed like in the following screenshot.
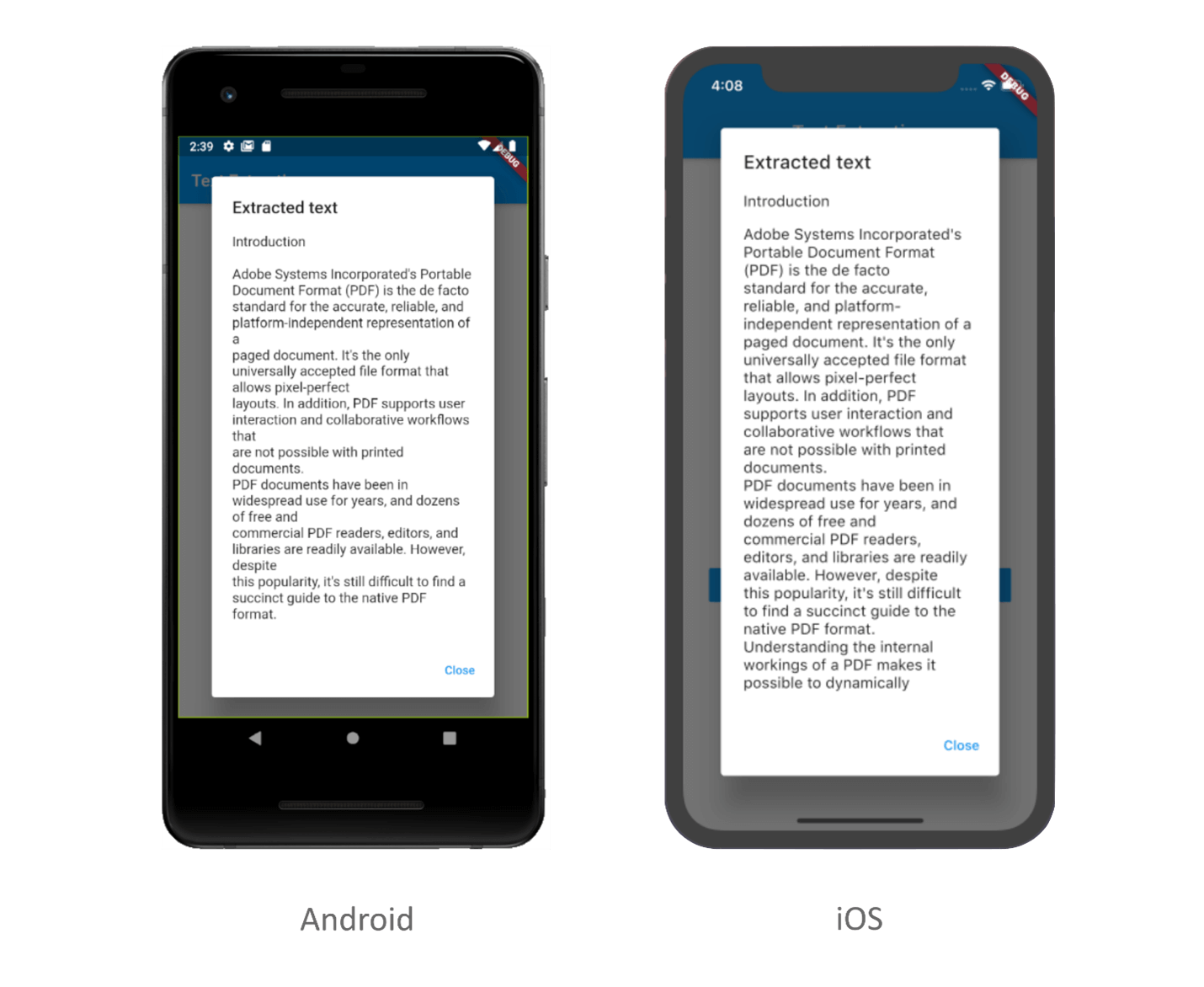
Extract text from predefined bounds
We can extract text from predefined bounds in an existing PDF document. To do this, we need to specify the bounds where the data we want is present in the PDF.
The following code example illustrates the procedure to extract text from specified bounds. Here, we are going to extract the invoice number in the PDF document.
//Load an existing PDF document.
PdfDocument document =
PdfDocument(inputBytes: await _readDocumentData('invoice.pdf'));
//Create a new instance of the PdfTextExtractor.
PdfTextExtractor extractor = PdfTextExtractor(document);
//Extract all the text from a particular page.
List<TextLine> result = extractor.extractTextLines(startPageIndex: 0);
//Predefined bound.
Rect textBounds = Rect.fromLTWH(474, 161, 50, 9);
String invoiceNumber = '';
for (int i = 0; i < result.length; i++) {
List<TextWord> wordCollection = result[i].wordCollection;
for (int j = 0; j < wordCollection.length; j++) {
if (textBounds.overlaps(wordCollection[j].bounds)) {
invoiceNumber = wordCollection[j].text;
break;
}
}
if(invoiceNumber != ''){
break;
}
}
//Display the text.
_showResult(invoiceNumber);
Executing the above code example will display the output text shown in the following screenshot.
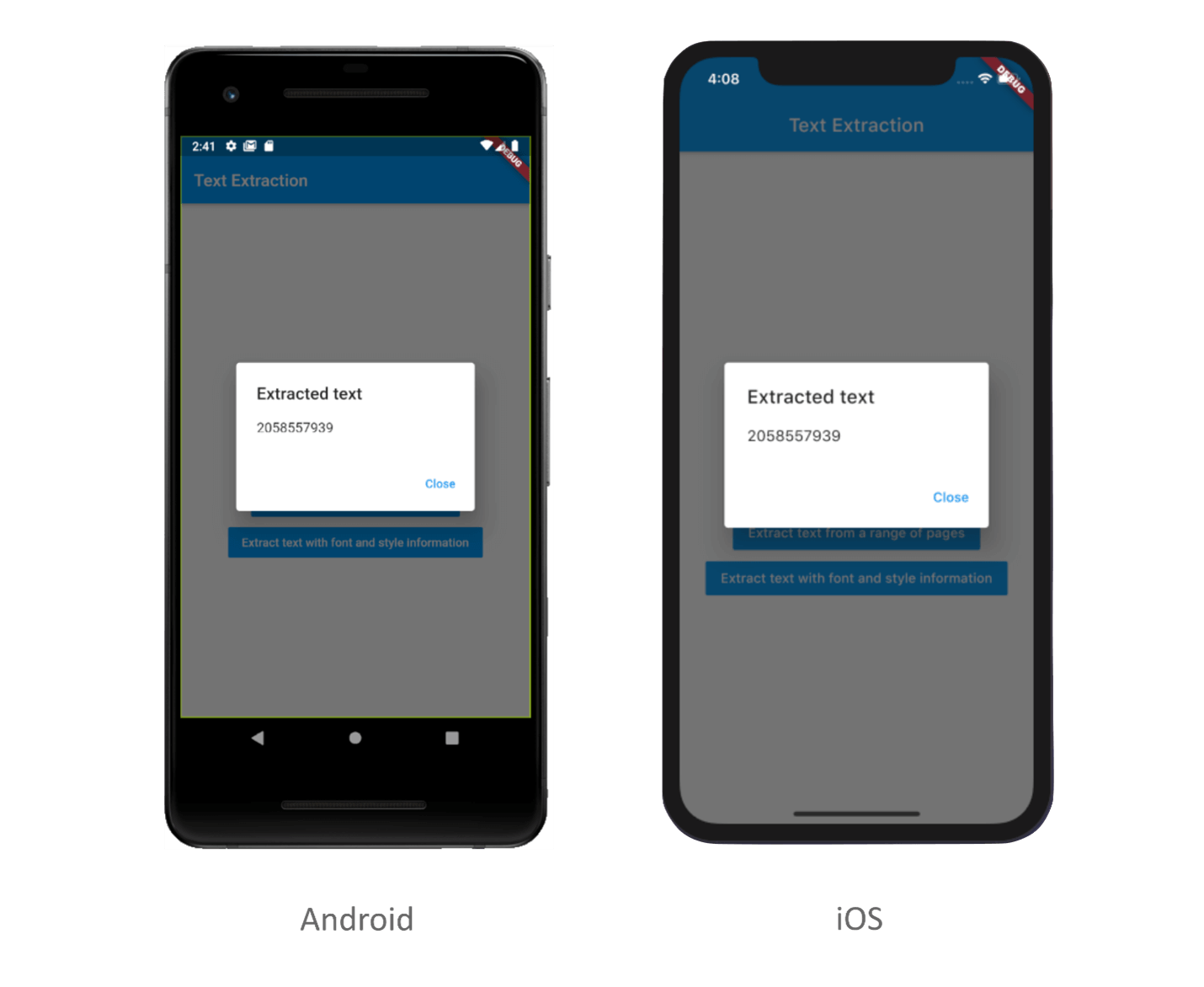
Extract text from a specific page
We can extract text from a particular page from a PDF document by passing the specific page index to the extractText method.
The following code example illustrates how to do this.
//Load an existing PDF document.
PdfDocument document =
PdfDocument(inputBytes: await _readDocumentData('pdf_succinctly.pdf'));
//Create a new instance of the PdfTextExtractor.
PdfTextExtractor extractor = PdfTextExtractor(document);
//Extract all the text from the first page of the PDF document.
String text = extractor.extractText(startPageIndex: 0);
//Display the text.
_showResult(text);
Executing the above code example will display the text from the first page like in the following screenshot.
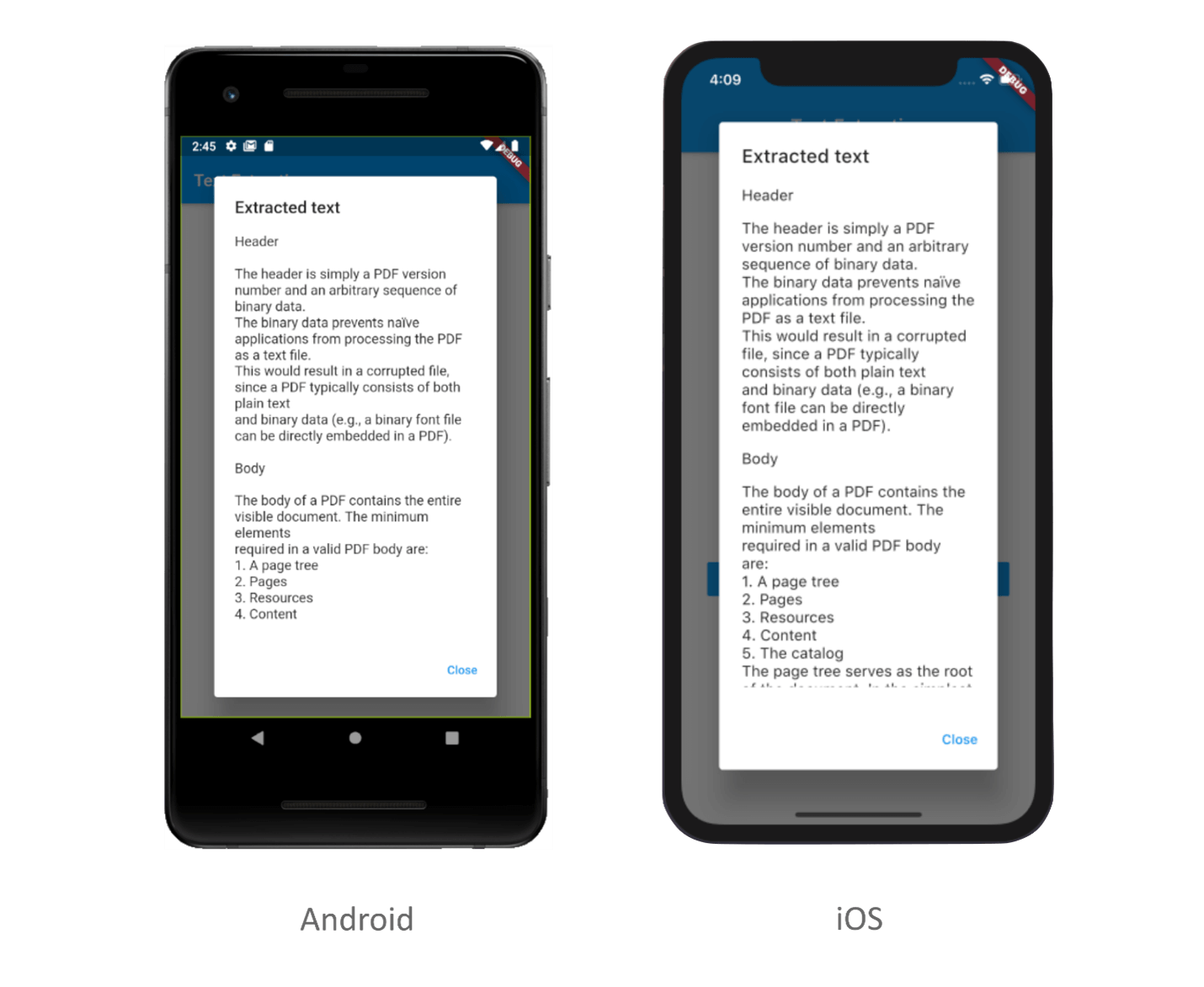
Extract text from a range of pages
We can also extract text from a range of pages in a PDF document by providing the start and end page indices to the extractText method. The following example illustrates how to extract text from a range of pages.
//Load the existing PDF document.
PdfDocument document =
PdfDocument(inputBytes: await _readDocumentData('pdf_succinctly.pdf'));
//Create the new instance of the PdfTextExtractor.
PdfTextExtractor extractor = PdfTextExtractor(document);
//Extract all the text from the first page to third page of the PDF document.
String text = extractor.extractText(startPageIndex: 0, endPageIndex: 2);
//Display the text.
_showResult(text);
Extract text with font and style information
You can also extract text with its bounds, font name, font style, and font size. The following code example illustrates how to extract text with its details.
//Load an existing PDF document.
PdfDocument document =
PdfDocument(inputBytes: await _readDocumentData('invoice.pdf'));
//Create a new instance of the PdfTextExtractor.
PdfTextExtractor extractor = PdfTextExtractor(document);
//Extract all the text from specific page.
List<TextLine> result = extractor.extractTextLines(startPageIndex: 0);
//Draw rectangle.
for (int i = 0; i < result.length; i++) {
List<TextWord> wordCollection = result[i].wordCollection;
for (int j = 0; j < wordCollection.length; j++) {
if ('2058557939' == wordCollection[j].text) {
//Get the font name.
String fontName = wordCollection[j].fontName;
//Get the font size.
double fontSize = wordCollection[j].fontSize;
//Get the font style.
List<PdfFontStyle> fontStyle = wordCollection[j].fontStyle;
//Get the text.
String text = wordCollection[j].text;
String fontStyleText = '';
for (int i = 0; i < fontStyle.length; i++) {
fontStyleText += fontStyle[i].toString() + ' ';
}
fontStyleText = fontStyleText.replaceAll('PdfFontStyle.', '');
_showResult(
'Text : $text \r\n Font Name: $fontName \r\n Font Size: $fontSize \r\n Font Style: $fontStyleText');
break;
}
}
}
//Dispose the document.
document.dispose();
Executing the above code example will provide the output shown in the following screenshot.
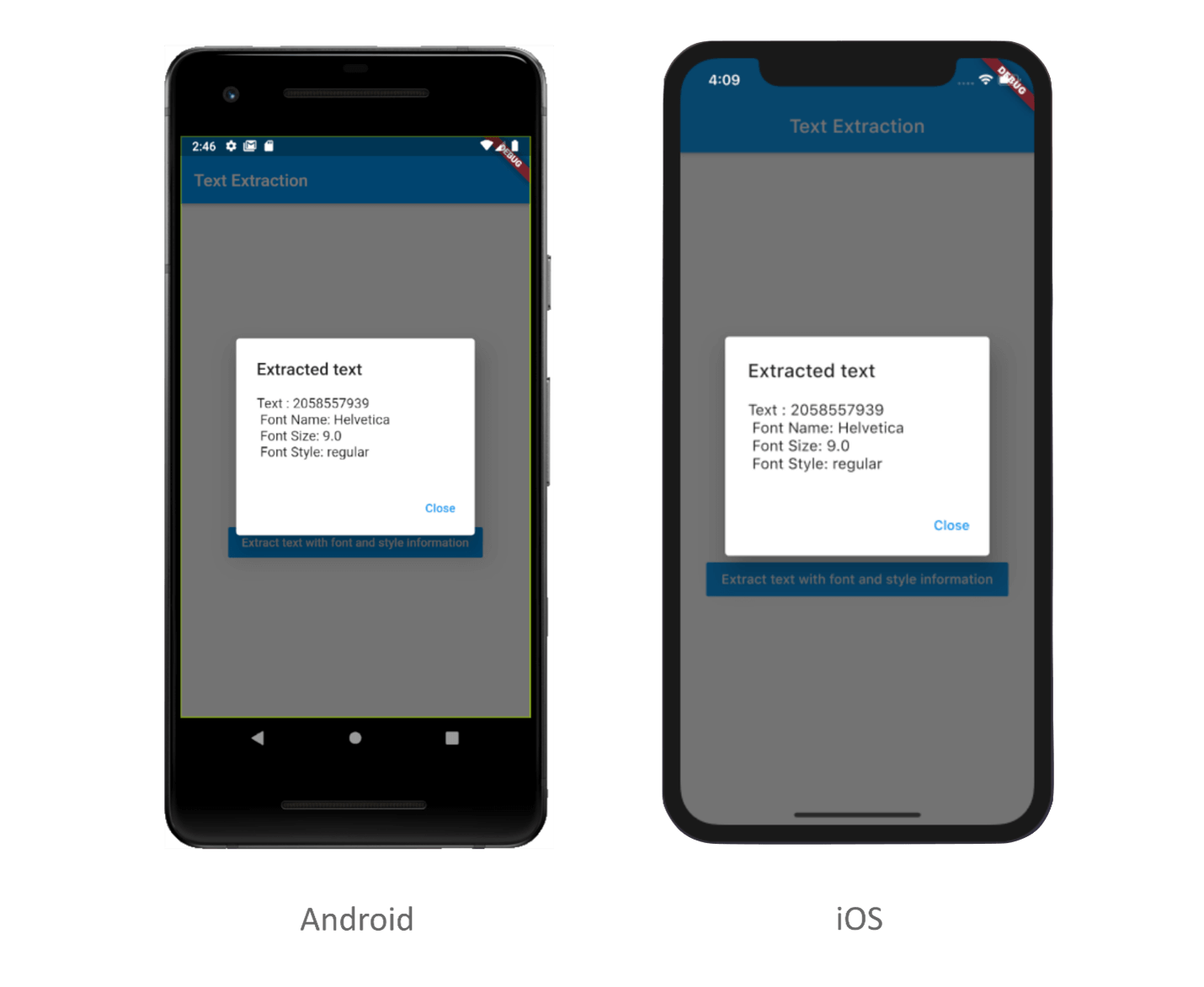
GitHub sample
You can check out samples for all these extraction types in this GitHub repository.
Conclusion
In this blog post, we have covered five different ways to extract text from a PDF document in Flutter applications using the Syncfusion Flutter PDF library. Take a moment to peruse our documentation, where you’ll find other options and features, all with accompanying code examples.
If you have any questions about these features, please let us know in the comments section below. You can also contact us through our support forums, Direct-Trac, or feedback portal. We are happy to assist you!

Related Blogs
If you like this article, we think you will also like the following articles about our PDF Library:
 No spam, just valuable updates.
No spam, just valuable updates.
Comments (2)
How do you deal with images?
Hi Alexandre Renaud,
Thanks for contacting Syncfusion support.
At present, we do not have support for extract image. We do not have any immediate plans to implement this feature. At the planning stage for every release cycle, we review all open features and identify features for implementation based on specific parameters including product vision, technological feasibility, and customer interest.
The status of these features can be tracked using following links.
https://www.syncfusion.com/feedback/21130/support-for-extracting-the-images-from-pdf-document
Regards,
Anand Panchamoorthi